Wer ist der Klügste?
Künstlich intelligent oder natürlich dumm?
Allein daran, wie überhaupt der Begriff (menschlicher) Intelligenz zu definieren ist, scheiden sich in der Fachwelt bereits die Geister. Die Frage, wann Handeln als „intelligent“ gelten darf, ist sogar überhaupt nicht entscheidbar, da reine Definitionsfrage. Standardisierte Tests wie die IQ-Skala sollen das Unbekannte quantifizieren, also mess- und vergleichbar machen, doch selbst die Vorbedingung, dass Intelligenz ein eindimensionales Phänomen ist, ist eigentlich ungeklärt. Doch dieser Artikel soll nicht die bohrenden Fragen der Psychologie und Hirnforschung klären (wozu der Autor ohnehin nicht kompetent wäre). Es soll hier um sogenannte künstliche Intelligenz (KI) gehen und dafür ergibt sich eine recht intuitive Definition: die möglichst genaue und glaubwürdige Nachbildung in der jeweiligen Situation sinnvoller menschlicher Verhaltensweisen.
Hierfür gibt es zwei Möglichkeiten: Man kann entweder den Entstehungsprozess als intelligent definierter Entscheidungen (oder sogar die Entstehung von Intelligenz selbst) ansehen oder aber man analysiert rein die Entscheidungen selbst, also die „Ausgabe“ bestehender Referenzintelligenz. Die Beantwortung der ersten Frage ist der exaktere, aber auch umfangreichere Weg, der den zweiten Ansatz aufgrund seiner Vollständigkeit subsumiert. Wüsste man, wie Intelligenz entsteht, dann könnte man diese Prozesse exakt nachbilden und hätte damit die perfekte künstlich geschaffene Intelligenz, die nicht von menschlicher zu unterscheiden wäre. Da jedoch weder Hirnforscher noch Soziologen hierzu eine abschließende Antwort liefern können, führen solche Überlegungen vorerst in eine weitere Sackgasse.
Es bleibt also die Variante des Beobachtens als intelligent wahrgenommenen Handelns und der Versuch deren Nachbildung mit beliebigen Mitteln, die nicht den originalen entsprechen müssen, allerdings innerhalb eines autonomen, nicht von außen gesteuerten Entscheidungsprozesses stattfinden. Letzterer Aspekt ist deshalb essentiell, da heutzutage künstliche Intelligenzen üblicherweise auf deterministischen Maschinen implementiert werden. Bei menschlichen Hirnprozessen handelt es sich dagegen wahrscheinlich um stochastische Prozesse, die bei Wiederholung zu unterschiedlichen Ergebnissen führen können. Die Kernfrage ist also: Kann man trotz dieses zentralen Unterschieds Modelle entwickeln, die menschlichen Beobachtern intelligent erscheinen?
Der Turing-Test: Vom Menschen nicht unterscheidbar?
Die Nagelprobe
Der Mathematiker Alan Turing formulierte dieses Problem 1950 in Form eines Tests: Ein Mensch kommuniziert über einen Computer (um andere optische und akustische Hinweise auszuschließen) mit einem ihm unbekannten Partner. Ob es sich dabei um einen anderen Menschen oder eine künstliche Intelligenz handelt, ist dem Probanden unbekannt. Kann der Mensch nachher nicht mit Sicherheit sagen, ob er mit einem Menschen oder einer Maschine geredet hat, obwohl letzteres der Fall war, hätte diese künstliche Intelligenz den Turing-Test bestanden.
Turing selbst postulierte damals, im Jahr 2000 sollten Computer so leistungsfähig sein, den Test bestehen zu können. Hiermit lag er jedoch leider falsch: Auch zehn Jahre später hat es noch keine noch so aufwändig entwickelte künstliche Intelligenz geschafft, überzeugend genug zu funktionieren.
ELIZA
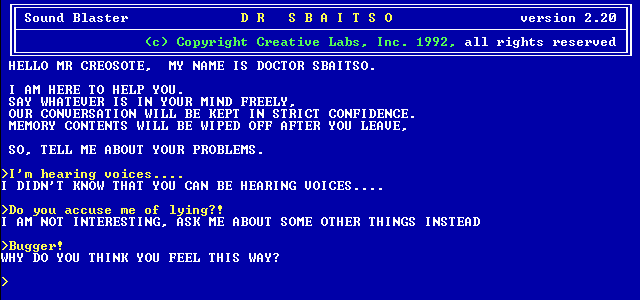
Mit ELIZA wurde 1966 ein Programm entwickelt, das sich sehr nahe am klassischen Turing-Test orientierte: Das Programm reagierte auf natürlichsprachige Texteingaben des Benutzers mit eigenen Aussagen oder Fragen, so dass sich eine Art Unterhaltung ergeben sollte.
Die bekannteste Ausprägung von ELIZA ist der „Psychotherapeut“: Dieser virtuelle Gesprächspartner machte es sich insofern relativ einfach, dass er die Aussagen des Benutzers semantisch analysierte und versuchte, den jeweiligen Kern als Frage umzuformulieren. „Ich denke, ich werde verfolgt.“ hätte mit „Wieso denkst du, du wirst verfolgt?“ beantwortet werden können.
Einerseits ist dies, sofern man dem Klischee glauben darf, die typische Masche zahlreicher Psychiater, um den Patienten zur Selbstreflektion zu bringen, andererseits aber nach kürzester Zeit eben auch nicht mehr überzeugend, da die „künstliche Intelligenz“ sichtbar nur auf Schlüsselworte reagiert – und diese teilweise in einen völlig falschen Kontext bringt. Vom Bestehen des Turing-Tests war ELIZA also weit entfernt. Trotzdem ist ELIZA als frühes „spielerisches“ Experiment insofern bedeutend, dass es heute als Wurzel zahlreicher Anwendungs- und Spielgenres gelten kann.
Elektronische Sieger: Besser als jeder Mensch?
Die Ziele des Turing-Tests sind sehr ehrgeizig und auch durchaus fragwürdig formuliert. Die Fähigkeit zu menschlicher Kommunikation in ihrer Gesamtheit ist nicht deckungsgleich mit intelligentem Verhalten. Der Test deckt nur die Schnittmenge zwischen Kommunikation und Intelligenz ab und weist jegliches nicht-verbal-kommunikatives Verhalten, das trotz allem als intelligent bezeichnet werden könnte, zurück. Auch wenn der Turing-Test also noch unlösbar ist, ist es trotzdem vorstellbar, andere spezialisierte Aufgabenstellungen bereits „intelligent“ berechnen lassen zu können.
Kürzlich machte ein Computer namens Watson Schlagzeilen, der in der US-amerikanischen Spielshow Jeopardy antrat und alle Rekorde brach. Sicherlich eindrucksvoll, aber ist dies bereits Intelligenz? Bei Jeopardy kommt es primär auf umfangreiches Faktenwissen an. Hierbei ist jedes moderne Informationssystem dank seiner praktisch unerschöpflichen Datenbanken, die in Sekundenschnelle durchsucht werden können, gegenüber noch so gebildeten Menschen im Vorteil.
Die Intelligenzleistung des Watson-Systems liegt also nicht in seinem Wissen selbst, sondern in den Routinen, die für das Textverständnis zuständig sind. Bei Jeopardy wird ein Begriff (in den Regeln der Show als „Antwort“ bezeichnet) „definiert“, ohne ihn zu nennen. Die Aufgabe der Kandidaten besteht darin, diesen Begriff zu erraten (in Form einer „Frage“). Die gegebene Definition muss also korrekt interpretiert werden, um die Frage richtig zu beantworten.
")
Watson musste also aus den verbalen Formulierungen die relevanten Schlüsselworte extrahieren, bevor er in seiner Datenbank nach möglichen Antworten suchen konnte. In diesem Prozess liegt, anders als beim Faktenwissen, der Vorteil der menschlichen Kontrahenten: Da natürliche Sprache nur teilweise festen Mustern folgt, ist dies eine nicht-triviale Aufgabe für eine deterministische Maschine, während Menschen die Bedeutung eines Satzes recht schnell und zuverlässig erfassen können.
Dies führte zu einigen auf die Zuschauer bizarr wirkenden Fehlinterpretationen seitens Watsons, d.h. die künstliche Intelligenz machte Fehler, die Menschen niemals unterlaufen wären. Diese Antworten, die völlig an der Fragestellung vorbeigingen, hielten sich häufigkeitstechnisch jedoch in solch einem geringen Maße, dass der Computer letztendlich mit weitem Vorsprung gegen seine menschlichen Kontrahenten gewann. Die künstliche Intelligenz hatte sich also als mehr als ausreichend erwiesen, das überlegene Faktenwissen auszuspielen.
Prinzipiell ähnlich, aber in der Gewichtung zwischen reinem Wissen und intelligenten Entscheidungsalgorithmen etwas stärker in Richtung letzterer ausgeprägt, liegen Schachcomputer: In diesem klar definierten, mit programmierbaren Regeln eingegrenzten Feld kann es kein menschlicher Spieler mehr mit den spezialisierten Rechnern aufnehmen.
Wiederum sind bei dieser Anwendung natürlich die schier endlose Datenbanken bekannter Partien und Strategien zu nennen, die einem Computer zur Verfügung stehen. Diese machen jedoch einen geringeren Anteil an der Gesamtleistung des Systems aus: Anders als bei Jeopardy gibt es beim Schach keine direkt „richtigen“ oder „falschen“ Entscheidungen im Sinne einer sofortigen Nachprüfbarkeit. Zwar muss ein guter Schachspieler schon über ein umfangreiches Wissen verfügen, Partien werden jedoch durch kluge und durchaus auch originelle (d.h. intelligente) Planung gewonnen.
Noch mehr als bei Watson stellt sich also bei Deep Blue und Konsorten die Frage, wie die deterministischen Rechenmaschinen zu ihren Entscheidungen kommen. Welche Figur soll in welcher Situation wohin bewegt werden, um den Gegner maximal unter Druck zu setzen?
Mathematische Grundlagen: Der Abschnitt, den eh alle überspringen
Entscheidungstheorie
Die Entscheidungstheorie bezeichnet die Gruppe der Methoden und Algorithmen, die sich mit Evaluation von Eingabewerten anhand vorgegebener Kriterien befassen. Es werden also für eine Entscheidung relevante Einflussfaktoren definiert, diese in einer zu definierenden mathematischen Funktion verarbeitet und das Ergebnis wird anschließend anhand möglicher Ausgabegruppen klassifiziert.
Dies kann auf sehr unterschiedliche Arten geschehen. Manche Klassifikatoren arbeiten mit Regeln, andere setzen direkt an der zu Grunde liegenden Stochastik an und jonglieren Zahlen. So sind auch einige Klassifikatoren für Menschen intuitiver verständlich als andere – jedoch ohne, dass es eine Korrelation mit der Qualität der Ergebnisse geben muss. Auch muss bei der Wahl der Verfahrens der Anwendungszweck bedacht werden.
Modellierung
Die erwähnte Funktion, mittels derer eine künstliche Intelligenz zu einer Entscheidung kommt, fällt jedoch leider nicht vom Himmel. Man kann die Ansätze, wie man die Vorarbeit erledigen kann, diese Funktion inhaltlich zu definieren, grob in drei Bereiche einteilen.
Expertenwissen
In vielen Anwendungsbereichen gibt es bereits menschliche Experten, die im betrachteten Feld gute Entscheidungen zu treffen fähig sind. Ihr Wissen kann in manuell in ein automatisiertes Entscheidungsmodell überführt werden, sofern eine Reflektion und Abstraktion der vielleicht bislang unbewussten Entscheidungskriterien möglich ist. Üblicherweise geschieht dies mittels Entscheidungsregeln, da diese den menschlichen Formulierungsfähigkeiten am nächsten kommen.
Das so erstellte Modell ist somit sehr gut nachvollzieh- und prüfbar. Das kann jedoch gleichzeitig die größte potentielle Schwäche dieses Vorgehens werden: Nennen die Experten unvorteilhafte Entscheidungskriterien oder gewichten sie diese auf unideale Weise, ist das daraus entstandene Entscheidungsmodell inhärent schwach. Diese Schwäche ist jedoch nicht mit den naheliegenden Mitteln feststell- oder nachweisbar. Das liegt daran, dass kein Fehler in der Umsetzung, d.h. beispielsweise der Programmierung des Modells vorliegt: Die Abbildung zwischen abstrakter, mathematisch-logischer und technischer Ebene ist exakt. Dass bereits die erste dieser Ebenen die Wurzel des Problems ist, ist formell nicht prüfbar, da ihre Erstellung nicht auf Formalismen beruht, sondern eben auf menschlich-subjektiver Einschätzung und Formulierungsfähigkeit.
Auch hat diese Methode natürlich Grenzen: Entscheidungsmodelle werden schnell sehr komplex. Diese Komplexität noch „per Hand“ in ein Modell zu gießen, ist irgendwann schlicht und einfach unmöglich.
Empirische Analysen
Ist eine direkte Umsetzung von Expertenwissen nicht möglich, kann wiederum die Mathematik weiterhelfen. Data Mining ist dabei der übliche Begriff, hinter dem letztlich meist nichts anderes als eine statistische Auswertung vorhandener Daten steckt.
Große Mengen protokollierten Verhaltens menschlicher Entscheider müssen als Voraussetzung vorhanden sein. Anhand dieser können sogenannte Mustererkennungsalgorithmen typisches Verhalten identifizieren und somit automatisch – im Rahmen ihrer vorbestimmten Möglichkeiten bestmöglich – abstrahieren. Man spricht in diesem Zusammenhang (je nach spezifischer Ausprägung des Algorithmus) auch von Clustering, also dem automatischen Erkennen von Gruppen in einer Datenmenge.
Neben der Voraussetzung des Vorliegens sehr großer Datenmengen ist die größte Schwäche der Entscheidungsfindung auf der Basis von Data Mining, dass hierdurch eben nicht versucht wird, eine möglichst „ideale“ Entscheidung zu treffen, sondern eine den vorliegenden Daten möglichst ähnliche. Die Annahme ist also, dass sich die Menschen, deren Daten analysiert wurde, „perfekt“ verhalten haben.
Andererseits muss dies nicht mal unbedingt ein Nachteil sein. Es entspricht genau der eingangs aufgestellten Definition künstlicher Intelligenz: Nachbildung menschlichen Verhaltens, das ja ebenfalls häufige Schwächen aufweist. Ob dies akzeptabel ist, hängt sehr vom Anwendungsfeld ab.
Darüber hinaus werden zahlreiche nur implizit in den Daten vorhandene Regeln, beispielsweise bestimmte Grenzwerte oder andere unmögliche Entscheidungen, nicht explizit in den automatisch erstellten Modellen vorkommen. Steuert eine künstliche Intelligenz beispielsweise eine Maschine, bei der nur diskrete Werte auf einer Skala von 1 bis 10 eingestellt werden können, ist es nicht prinzipiell ausgeschlossen, dass manche Modelle künstlicher Intelligenz auch nicht-ganzzahlige Werde ausspucken. Solche Randbedingungen (wie im genannten Beispiel die Ganzzahligkeit) müssen deshalb unter Umständen wieder per Hand nachgepflegt werden.
Adaptive Systeme
Entscheidungsmodelle, wie auch immer sie initial erstellt wurden, müssen nicht statisch sein. Daten, die später während des produktiven Betriebs anfallen, können wiederum verwendet werden, um die bisherigen Entscheidungsmodelle anzupassen, also das neu hinzugewonnene Wissen mit in die Entscheidungsprozesse einfließen zu lassen.
Der bereits bemühte Schachcomputer könnte also den Verlauf der Partien, die gegen ihn gespielt wurden, ebenfalls abspeichern. Hat die künstliche Intelligenz die letzte Partie verloren und versucht der menschliche Gegner wieder die gleiche Taktik, könnte die künstliche Intelligenz diesmal anders reagieren, da sich die vorherige Taktik, wie sie mittlerweile gelernt hat, als nicht erfolgreich erwiesen hat.
Die Gefahr eines selbstständig lernenden Systems ist, dass sich nicht-ideale Entscheidungsmuster mit der Zeit immer weiter verstärken können. Das System passt sich an diejenigen Daten an, die es bekommt. Sind beispielsweise die ersten Datenmengen nicht repräsentativ, prägen diese das Entscheidungsmodell jedoch besonders stark – wodurch später nur schlechtere Ergebnisse erzielt werden können. Das liegt an einer Art Lawineneffekt: Wird ein System schlecht initialisiert und werden diese Entscheidungsmuster praktisch angewandt, führt dies zu einer weiteren Verstärkung dieser Muster, da ein unbeaufsichtigt selbstlernendes System üblicherweise das Auftreten bekannter Muster als Verstärkungsfaktor dieser Regeln benutzt.
Beispiel
Im Folgenden soll ein einfaches Beispiel erläutert werden, wie rein durch „Expertenwissen“ ein anwendbares Modell für einen Schachcomputer erstellt werden kann. Das Modell soll statisch sein.
Üblicherweise lernen Anfänger, dass die Figuren einen zueinander relativen „Wert“ besitzen.
| Figur | Wert |
|---|---|
| Bauer | 1 |
| Pferd | 3 |
| Läufer | 3 |
| Turm | 5 |
| Dame | 9 |
| König | ∞ |
Diese Einordnung kann, von Menschen wie künstlichen Intelligenzen, als Grundlage benutzt werden, die Entscheidung zu treffen, welche eigene Figur man bewegen möchte. Ein vollständiges Entscheidungsmodell könnte folgendermaßen aussehen:
1. Stelle alle möglichen (regelkonformen) Bewegungen aller eigenen Figuren fest.
2. Ordne jeder dieser Bewegungen einen Wert V(b) zu, der dem Wert der gegnerischen geschlagenen Figur entspricht (wenn nichts geschlagen wird: 0).
3. Ordne jeder Bewegung einen Wert V(w) zu, der dem Wert der eigenen Figur entspricht, die durch die Bewegung „ungedeckt“ endet (d.h. auf einem Feld, das keine eigene Figur im folgenden Zug erreichen könnte) und von einer gegnerischen Figur geschlagen werden könnte. Bleiben mehrere Kandidaten (sind also mehrere eigene bedrohte Figuren ungedeckt), wird der höchste Wert angenommen.
4. Berechne für jede Bewegung die Differenz G = V(b) – V(w).
5. Wähle die Bewegung mit maximalem G. Gibt es mehrere Kandidaten mit gleichem G, wähle denjenigen mit maximalem V(b). Gibt es immer noch mehrere Kandidaten, wähle den ersten der Liste.
6. Führe die gewählte Bewegung aus.
Dieses verbal beschriebene Modell ist programmierbar und deterministisch. Insbesondere die zusätzlichen Regeln im fünften Schritt sind hierfür essentiell: Konflikte mehrerer Entscheidungskandidaten müssen regelbasiert aufgelöst werden können – selbst eine zufällige Wahl wäre hierfür ein legitimes Mittel. Grundvoraussetzung für jedes Entscheidungsmodell ist es, dass keine undefinierten (und damit unentscheidbaren) Zustände auftreten.
Das dem Modell zugrundegelegte Optimierungskriterium, und damit die „Spielstrategie“, die diese künstliche Intelligenz verfolgen würde, ist:
V(b) – V(w) = max
Durch den zweiten Satz des fünften Schrittes wird das Vorgehen zu einer reinen Vernichtungsstrategie: Wenn es die Möglichkeit gibt, gegnerische Figuren mit positiver oder neutraler Punktebilanz zu schlagen, wird dies auch getan.
Die Optimierung ist zeitlich gesehen jedoch rein lokal: Es wird nur der momentane Stand auf dem Spielbrett betrachtet, also werden weder Zughistorie, noch mögliche Zukunft über den direkt folgenden Zug des Gegners hinaus mit in die Überlegungen mit einbezogen. Diese künstliche Intelligenz hätte also keinen „Plan“ im klassischen Sinne. Taktische Opfer höherwertiger Figuren mit dem Ziel eines mittelfristigen Vorteils würde sie niemals vornehmen.
Damit, einen gegnerischen König matt zu setzen, hätte die KI ebenfalls Probleme, da ein systematisches „Einkesseln“ über mehrere Züge nicht vorgesehen ist. Wenn sich der KI jedoch die Möglichkeit bietet, den gegnerischen König zu schlagen, wird sie dies aufgrund des als unendlich bemessenen Wertes dieser Figur auch in jedem Fall tun – das Wissen über das zentrale Spielziel ist also im Modell enthalten und adäquat abgebildet.
Aufgrund der Einschränkungen würde diese KI natürlich selbst gegen Anfänger keinen Blumentopf gewinnen. Jedoch wäre sie fähig, an regelkonformen Schachpartien teilzunehmen und nachvollziehbare Zugentscheidungen zu treffen. Das Modell fällt also tatsächlich bereits in die Klasse künstlicher Intelligenzen, da eine autonome Entscheidungsfindung stattfindet, auch wenn es noch keine hochwertige, spielstarke ist. Doch auch menschliche Spieler sind ja irgendwann mal Anfänger und stellen dann zunächst genau solche Überlegungen für ihre eigenen Entscheidungen an.
Eine naheliegende Erweiterung des Modells wäre beispielsweise, die Qualität der eigenen Deckung mit einzubeziehen. Im Grundmodell ist die Annahme, dass der Gegner niemals Figuren schlagen wird, die gedeckt sind. Jedoch ergeben sich in der Praxis häufig Ketten, in denen über mehrere Züge wechselseitig geschlagen wird.
Um dies abzubilden, könnte man den Wert der gedeckten Figur V(w) mit dem Wert der deckenden Figur V(w2) in Beziehung setzen. Eine Möglichkeit wäre es, wieder die Differenz V(w2) – V(w) zu betrachten: Diesmal müsste die Differenz jedoch nicht maximiert, sondern minimiert werden, was bedeutete, dass man möglichst höherwertige mit niederwertigen Figuren zu schützen versucht, was erstmal sinnvoll erscheint.
Zusätzlich wären allerdings natürlich weitere Faktoren zu berücksichtigen: Die Anzahl der eigenen schützenden Figuren, die Anzahl der gegnerischen bedrohenden Figuren, deren jeweilige Werte usw. Das schön simple eindimensionale obige Entscheidungsmodell würde also schnell n-dimensional, was im Rahmen dieses Artikels nicht mehr darstellbar und wahrscheinlich auch nicht mehr direkt verständlich wäre. Das Vorgehensschema bliebe jedoch das gleiche.
Wer es ganz genau wissen möchte
Wie erwähnt existieren zahlreiche Methoden in diesem Bereich der Mathematik, über die jeweils bereits für sich ganze Bücher verfasst wurden. Jedes dieser Themen ist jeweils für sich durchaus interessant, es führte jedoch zu weit, ihnen hier im Detail nachzugehen. Folgende Stichworte könnten bei tiefergehendem Interesse Ansätze liefern:
Maximum-A-Posteriori (MAP) – Methode
Maximum-Likelihood (ML) – Methode
Bayes-Klassifikation
Entscheidungsbäume
Neuronale Netze
Nächste-Nachbarn-Klassifikation („Lazy“)
Regressionsverfahren
Fuzzy-Logik
Gelungene (?) künstliche Intelligenz
Im Folgenden sollen nun schlaglichtartig Beispiele aus dem Bereich der Computerspiele für ge- und misslungene künstliche Intelligenzen diskutiert sowie Abgrenzungen zu deutlich nicht-intelligenten Verhaltensregeln aufgezeigt werden. Das heißt: Wo findet sich überhaupt künstliche Intelligenz, wo laufen einfach nur sich wiederholende, nicht intelligente Programme ab?
Brettspiele: Licht und Schatten
Wie am Schachbeispiel zu sehen, sind Spiele mit klar definierten und begrenzten Handlungsmöglichkeiten und Regeln für künstliche Intelligenzen relativ leicht zu verarbeiten. Eine künstliche Intelligenz, die relativ trivial zu programmieren gewesen sein sollte, die aber trotzdem sehr wirkungsvoll spielt, bietet Die total verrückte Rallye. Dort ist es das Ziel, auf einer Europakarte auf vorgegebenen Straßen mittels eines handelsüblichen Würfels möglichst schnell vorgegebene Hauptstädte zu erreichen.
")
Das Optimierungskriterium ist also klar: Es ist die kürzeste Route zwischen der Spielfigur und der Zielstadt zu finden. Dieses mathematische Problem ist mit dem sogenannten Dijkstra-Algorithmus deterministisch lösbar. Eine weitere Dimension ergibt sich durch die positiven und negativen Ereignisfelder, auf denen der Spieler auf dem Weg landen kann. Deren Einfluss kann jedoch beispielsweise durch einen zusätzlichen Summanden von ±1 abgebildet werden.
Doch nicht immer gelingen solche scheinbar recht einfachen Optimierungen. Winpolis ist eine Computerumsetzung von Monopoly. Dessen Computergegner auf den ersten Blick einigermaßen konkurrenzfähig wirken. Jedoch stellt sich schnell heraus, dass deren Entscheidungsmuster rein lokal, d.h. kurzfristig optimieren: Angebote, ihnen Straßen gegen Bargeld abzukaufen, nehmen sie dann an, wenn die Kaufsumme ein Vielfaches des ursprünglichen Kaufpreises (d.h. angenommenen Wertes) beträgt.
")
Dies ist nach lokaler Optimierung ein nachvollziehbares Handeln: Straße X ist 5.000 DM wert, das Angebot beträgt 20.000 DM – damit ist es vorteilhaft, den Kaufvertrag abzuschließen, da der Reingewinn 15.000 DM beträgt. Dass in den folgenden Runden nun jedoch der menschliche Spieler diese Straße besitzt und damit ordentlich Miete kassieren wird, auch vom vormaligen Besitzer, wird nur unzureichend in Betracht gezogen. 15.000 DM, also der angenommene Überschussgewinn, entspricht dem typischen Preis, den man zahlen muss, wenn man ein einziges Mal auf ein voll ausgebautes Grundstück kommt. Bereits nach einer einzigen Runde kann der Profit also wieder verloren sein. Winpolis benutzt also eine künstliche Intelligenz, jedoch keine sonderlich spielstarke, d.h. in ihrem abgegrenzten Aufgabengebiet wirkungsvolle.
Simulierte Menschen: Teilerfolge
")
Ein Klassiker der künstlichen Intelligenz außerhalb des wissenschaftlichen Bereichs ist Little Computer People. In diesem „Spiel“ beobachtet man einen Menschen in seinem Haus: Er bekommt Hunger, geht also zum Kühlschrank und bereitet sich eine Mahlzeit zu. Sein Hund will ausgeführt werden, also gehen die beiden los. Das ist genau das, was künstliche Intelligenz ausmacht: die Nachbildung menschlichen Handelns. Die Rolle des Menschen vor dem Bildschirm ist dabei minimal: Man kann versuchen, per Texteingabe mit dem virtuellen Menschen zu kommunizieren. Dies geschieht im Imperativ – man fordert ihn zu bestimmten Handlungen auf, die dann entweder durchgeführt oder aufgrund anderer Prioritäten zurückgewiesen werden.
Auch wenn die Werbeanzeigen es damals anders versprachen, kann Little Computer People jedoch keiner wissenschaftlichen Betrachtung standhalten. Die Autonomie, die der simulierte Mensch an den Tag legt, ist letztlich sehr beschränkt, die Handlungsmöglichkeiten sind zu gering. Es ist eine künstliche Intelligenz – das wird spätestens klar, wenn der Spieler versucht, dem Menschen Anweisungen zu geben, die dieser verweigert. Sie deckt jedoch ein zu geringes Spektrum ab, um tatsächlich im Turing'schen Sinne zu überzeugen. Außerhalb der lustigen Werbeanzeigen hatte das Spiel diesen Anspruch aber wohl auch nie.

Praktisch das gleiche Konzept verfolgte 15 Jahre später Die Sims. Abgesehen von spielerischen Erweiterungen, wie der Möglichkeit, Haus und Garten selbst zu gestalten und einzurichten, ist die Grundlage genau wie bei Little Computer People die Interaktion zwischen dem Spieler vor dem Bildschirm und virtuellen Charakteren im Spiel. Interessant ist Die Sims im Rahmen dieses Artikels vor allem dadurch, dass es seine intern genutzten Entscheidungskriterien teilweise sichtbar macht: Attribute der zu steuernden Charaktere wie „Hunger“ oder „Spaß“ (Laune) werden am unteren Bildschirmrand angezeigt. Verschiedene Aktionen wirken sich (und auch das ist im Spiel dokumentiert) auf einen oder mehrere dieser Aspekte positiv oder negativ aus: Essen lindert Hunger, steigert aber den „Harndrang“-Wert. Bahnen im Pool zu schwimmen macht Spaß, zehren aber am „Energie“-Wert. Die Entscheidungen, was ein Charakter tut, wenn der Spieler ihn in Ruhe lässt, oder auch die Frage, ob der Charakter einer Anweisung des Spielers folgt, hängt direkt und nachvollziehbar von diesen Werten ab: Befindet sich alles – im wahrsten Sinne des Wortes – im „grünen Bereich“, hat der Spieler fast freie Kontrolle über den Charakter. Drängt jedoch ein Bedürfnis sehr, wird die künstliche Intelligenz entscheiden, Anweisungen zu verweigern oder sogar eigenständig die Entscheidung zu treffen, bestimmte lindernde Aktionen vom Spieler unsanktioniert durchzuführen.
")
Weniger ambitioniert, aber für seinen Zweck absolut ausreichend, gibt sich Skool Daze. Hier laufen gleich mehrere Dutzend simulierte Menschen durch ein virtuelles Schulgebäude und gehen scheinbar intelligent ihren jeweiligen Tätigkeiten nach: Unterrichtsstunden, Pausen und alles, was sonst noch so zum Schulalltag gehört, ist adäquat zu sehen. Der Spieler übernimmt die Rolle eines Schülers, der versucht, seine eigene Akte aus dem Schulsafe zu stehlen – hierzu müssen die Lehrer so manipuliert werden, dass sie die Zahlenkombination verraten. Dabei muss man jedoch gleichzeitig im normalen Schulalltag möglichst unauffällig bewegen, d.h. scheinbar den durch den Stundenplan vorgegebenen Bahnen folgen.
Man muss bei diesem Spiel trotz der großen Anzahl „handelnder“ Charaktere in Zweifel ziehen, dass irgendwelche Algorithmen künstlicher Intelligenz angewandt werden. Keine der sichtbaren Handlungen benötigen tatsächlich autonom entscheidende Charaktere; alles wird wahrscheinlich einfach durch ein globales, zeitgesteuertes Ereignissystem, d.h. eine Art „Gottfunktion“, die alle Figuren gleichermaßen steuert, abgewickelt. Die erste Unterrichtsstunde beginnt? Bewege Lehrer A in Klassenraum 1, Lehrer B in Klassenraum 2 usw.
Dies ist keine künstliche Intelligenz, da diese Muster vorprogrammiert sind und nicht auf Basis des aktuellen Zustands frisch errechnet werden. Dazu kommen einfachste Reaktionen auf unvorhergesehene Ereignisse: ein Schüler steht mitten im Unterricht auf – Lehrer reagiert mit „Setz dich hin!“. Man sieht also: Künstliche Intelligenz ist nicht unbedingt notwendig, um eine scheinbar lebendige Welt zu simulieren. Besser eine gelungene statische Simulation, wie Skool Daze zeigt, als eine misslungene künstliche Intelligenz.
Reaktionswunder: Taktische Vorteile
")
Neben endlosen Datenbanken, die bei Quizspielen wie Jeopardy helfen, haben Computer einen weiteren Vorteil gegenüber Menschen: Sind sie erstmal mit Entscheidungskriterien ausgestattet, können sie innerhalb von Bruchteilen von Sekunden entscheiden. Während ein Mensch erst erst eine Situation, die eine Entscheidung erfordert, erfassen muss, geschieht dies bei Computern praktisch ohne Verzögerung. Dies ist ein klarer Vorteil bei Spielen, bei denen schnelle Reaktionsgeschwindigkeit ein entscheidender Erfolgsfaktor ist.
Ein typisches Genre, wo dies der Fall ist, sind Sportspiele. Bei simulierten Mannschaftssportarten wie Fußball oder Eishockey müssen den Haken des ballführenden Spielers gefolgt und zur richtigen Zeit Maßnahmen zum Abnehmen ergriffen werden. Schüsse aufs Tor können in einer unglaublichen Geschwindigkeit näher kommen – muss man erst nachdenken, in welche Richtung man den Torwart steuert, mit welcher Taste das überhaupt funktioniert und das dann auch noch mittels der unidealen Schnittstelle „Hand-Steuergerät“ umzusetzen, ist es eventuell bereits zu spät. All das ist kein Problem für eine künstliche Intelligenz.
")
Man rast in einem Rennspiel auf eine Kurve zu? Der menschliche Spieler kann sich hier nur auf sein Gefühl und seine Erfahrung verlassen. Eine künstliche Intelligenz kennt dagegen die mathematische Beschreibung (Krümmung und Verlauf) der Kurve. Dadurch stehen ihr sämtliche Mittel der Optimierung der Fahrspur sowie der Regelungstechnik zur Verfügung. Nicht nur das, die künstliche Intelligenz kann problemlos diese komplexen mathematischen Methoden rechtzeitig (d.h. vor Erreichen der Kurve) anwenden. Die Beispiele zeigen: Wenn es ums (berechenbare) Reagieren geht, sind künstliche Intelligenzen gegenüber Menschen im bereits Vorteil.
Schnelle Strategen: Was ist daran bitte intelligent?
Doch auch in weniger sportlichen Disziplinen kommt genau dieser Effekt zum Tragen. Sogenannte Echtzeitstrategiespiele, d.h. Kriegsspiele, bei denen man nicht in Ruhe Runde für Runde überlegen kann, begannen bezüglich ihrer künstlichen Intelligenz ursprünglich recht vielversprechend: Früher Vertreter wie Modem Wars oder Command H.Q. zeigten sich in ihrer Spielstärke gegenüber menschlichen Spielern durchaus konkurrenzfähig.
")
Ausgerechnet das Spiel, das jedoch das Genre auf unbestimmte Zeit prägen sollte, ging einen anderen Weg: In Dune 2 gibt es keine nennenswerte künstliche Intelligenz. Stattdessen wird dadurch Gefahr aufgebaut, dass die computergesteuerten Gegner im Gegensatz zum Menschen nicht bei Punkt Null anfangen: Sie verfügen bereits über gut verteidigte Produktionsanlagen und überlegene Armeen, müssen diese nicht erst aufbauen. In festen Zeitintervallen werden ihnen zusätzlich regeltechnisch bedingt weitere Soldaten „geschenkt“, die sie dann allerdings auf primitivste Art und Weise einsetzen: Sie tauchen immer an den gleichen Stellen auf und bewegen sich immer auf den selben vorbestimmten Bahnen. Hat der Spieler dieses Schema durchschaut, kann er problemlos offensichtliche „Fallen“ stellen, in die die Computergegner zuverlässig jedes Mal hineinlaufen – sie ändern ihre Taktik niemals, lernen nicht aus erfolglosen Versuchen.
Warum kann das trotzdem für den Spieler zur Gefahr werden? Die regeltechnische Bevorzugung wurde bereits erwähnt, zweitens tritt der gleiche Effekt wie bei den Sportspielen ein: Während ein Mensch erst anhand der optischen oder akustischen Reize überhaupt darauf aufmerksam werden muss, dass Entscheidungen erforderlich sind und dann mittels eines spielspezifischen, üblicherweise mausbasierten Interfaces versuchen muss, so schnell wie möglich das Beste herauszuholen, kann ein Computer problemlos hundert Panzern gleichzeitig neue Befehle geben. Eine künstliche Intelligenz auf niedrigster Ebene, d.h. zur Detailsteuerung von militärischen Einheiten („Drehe dein Geschütz nach rechts und feuer auf den Gegner!“), existiert also selbst in Dune 2 und Konsorten – für eine „Strategie“ ist sie jedoch gar nicht erst zuständig.
")
Dass das auch anders geht, zeigt Z. In diesem humoristisch-zynisch angehauchten Kriegsspiel geht es um die Eroberung von in „Sektoren“ eingeteilte Landstrichen. Die Aktionen des Computergegners sind dabei sichtbar und stellen sich dadurch als nachvollziehbar „intelligent“ heraus: Hier versucht augenscheinlich eine künstliche Intelligenz, das Spiel ernsthaft, d.h. ebenso wie ein Mensch, zu spielen. Erstmal recht eindrucksvoll, die Grenzen dieser künstlichen Intelligenz zeigen sich jedoch, nachdem der hektische Anfang jeder Mission überstanden ist: Hat es der Spieler erst einmal bis zu einer relativ stabilen, ausgeglichen taktischen Situation geschafft, fehlt es der künstlichen Intelligenz an Konzepten und Ideen, weiterhin gefährlich zu bleiben. Darüber hinaus schlägt auch das andere Problem des Genres zu: Der Computer hat Startvorteile, wahrscheinlich wieder, um den Schwierigkeitsgrad für den Menschen zu heben.
Leider setzte sich in diesem Bereich die Variante aus Dune 2 durch: Z blieb einer der wenigen Versuche, eine das gesamte Spiel umfassende künstliche Intelligenz umzusetzen. Der Trend ging genau in die andere Richtung. Spiele wie MechCommander verlassen sich, um Spannung und Schwierigkeit zu erzeugen, komplett auf „geskriptete“ Ereignisse: Sobald die Roboter des Spielers einen bestimmten Punkt auf der Landkarte erreichen, tauchen beispielsweise plötzlich neue Gegner an unerwarteter Stelle auf, die den bisherigen Plan des Menschen sehr leicht zu Nichte machen könnten. Mit künstlicher Intelligenz hat das nichts mehr zu tun und aus Sicht des menschlichen Spielers auch wenig mit „Strategie“ – Erfolg durch Auswendiglernen der Ereignisse.
Strategische Versager
Leider gibt es dafür, dass indiskutable künstliche Intelligenzen es trotzdem in kommerziell vertriebene Produkte geschafft haben, ebenfalls (zu) viele Beispiele. Ein rundum interessantes hierfür ist Diplomacy, Avalon Hills Computerumsetzung ihres eigenen berühmten Brettspiels. Nun geht es bei Diplomacy, wie der Name schon sagt, primär um Diplomatie – diese ist jedoch, zumindest was die computergesteuerten Spieler angeht, komplett ausgespart.
")
Die naheliegende Vermutung, dass sich die Programmierer einfach nicht in der Lage sahen, eine sinnvolle künstliche Intelligenz, die diplomatische Verhandlungen mit den menschlichen Spielern führen kann, zu entwerfen und zu programmieren, wird vor allem dadurch genährt, dass auch das restliche Verhalten der Computergegner bodenlos ist. Obwohl die tatsächlichen Aktionsmöglichkeiten von Diplomacy sehr überschaubar sind (was als eines der größten Stärken des Spiels angesehen wird), sie also für eine künstliche Intelligenz leicht nachzubilden wären, kommt es in jeder Runde zu bizarren, keinesfalls nachvollziehbaren Fehlentscheidungen – bis dahin, dass der Computer schonmal „vergisst“, seine Figuren überhaupt zu ziehen. Ersetzt hier ein Zufallsgenerator die künstliche Intelligenz?
")
Nicht ganz so misslungen, aber immer noch schwer nachvollziehbar, zeigt sich die Programmierung der Steuerungsroutinen in North & South. Die eingesetzten Elemente künstlicher Intelligenz sind größtenteils akzeptabel, wenn auch nicht sonderlich stark. Jedoch kommt es in Schlachtszenen, in denen ein Fluss oder eine Schlucht das Feld durchzieht, zum Totalausfall: Der Computer benutzt einen Suchalgorithmus, um seine Soldaten in die Nähe der vom Menschen gesteuerten zu bringen. Die kürzeste Strecke zwischen zwei Punkten ist bekanntermaßen die Gerade, die die beiden verbindet. Ganz so primitiv, immer diesem Grundsatz zu folgen, ist dieser Suchalgorithmus zwar nicht, aber beinahe. Platziert man seine eigenen Leute nahe genug an der einen Seite der Schlucht, nimmt der Computer, dessen Männer sich auf der anderen Seite befinden, nicht mehr etwa die intakte Brücke, sondern schickt sie sehenden Auges direkt auf seine Gegner zu – d.h. in die Schlucht hinein, was zum sofortigen Tod führt. Zwar ist dieses Spiel nicht gerade eine ernstgemeinte Kriegssimulation, jedoch ist dies sicherlich nicht beabsichtigt gewesen.
Beinahe noch unzulänglichere Wegfindungsalgorithmen kommen im zivilen Sektor bei Transport Tycoon zum Einsatz. Hier bauen Mensch und Computer Transportwege zu Luft, Land und Wasser auf. Bei Flugzeugen und Schiffen zeigt es sich weniger, doch was die computergesteuerten Logistikfirmen beim Straßen- und Schienenbau veranstalten, ist einfach völlig unerklärlich.
Welchen Grund könnte es wohl haben, Gleise mehrmals um sich selbst im Kreis zu „wickeln“, nur um dann doch wieder zum Ausgangspunkt zurückzukommen? Oder wie kommt es, dass eine winzige, durch einen Menschen strategisch platzierte Schiene für den computergesteuerten Bauherren plötzlich ein unüberwindliches Hindernis darstellt?
")
Wie weit sind wir, oder: Für welche Spiele sollte man weiterhin Freunde einladen?
Wie gut künstliche Intelligenz funktioniert, hängt trotz aller Fortschritte der letzten Jahrzehnte weiterhin stark vom Anwendungsgebiet ab. Auftrumpfen können solche Systeme bereits in Bereichen, in denen Zugang zu großen Datenmengen einen entscheidenden Einfluss auf den Erfolg haben. Ähnlich verhält es sich in Anwendungsfällen, in denen es auf schnelle Reaktionen ankommt: Die automatisierte Entscheidungsfindung und -umsetzung durch einen Computer übertrifft in ihrer Geschwindigkeit die Reaktionszeiten jedes Menschen. Das allein gleicht teilweise vielleicht inhaltlich nicht ganz ideale Entscheidungen ohne Weiteres aus.
Schwieriger wird es, wenn die abzudeckenden „Regeln“ weniger klar und deutlich sind. Je freier die Entscheidungsmöglichkeiten sein sollen, je größer die Spielräume, desto schwieriger wird es, überhaupt sinnvolle Entscheidungsmodelle zu entwickeln und desto schlechter sind deren Ergebnisse. Hier ist im wissenschaftlichen Bereich noch einiges zu erforschen.
Bis dahin behelfen sich kommerzielle Computerspiele mit nicht-intelligenten Steigerungen der Herausforderung: Computergesteuerte Spieler werden regeltechnisch bevorzugt, starten mit zusätzlichen Ressourcen gegenüber den menschlichen Spielern, bekommen in bestimmten Spielsituationen einfach Dinge „geschenkt“ usw. Solche Taktiken mögen Spiele für den Menschen schwieriger machen, sind aber nur eine Notlösung – denn letztendlich ist solche „Schummelei“, sobald sie auffällt, ein Frustfaktor.
Bevor man sich also an die Umsetzung einer künstlichen Intelligenz wagt, die dann vielleicht vom menschlichen Spieler als schwach wahrgenommen wird, muss man sich fragen, ob es eventuell auch anders geht. Viele Spielprinzipien können komplett ohne intelligente Entscheidungsfindung auskommen – und wie gezeigt trotzdem nicht nur leblose Steine simulieren.
In dem eingangs erwähnten Jeopardy-Computerspiel findet sich beispielsweise überhaupt keine künstliche Intelligenz. Sind die Computergegner an der Reihe, wird einfach per Zufallsgenerator bestimmt, ob sie eine richtige oder falsche Antwort geben – völlig ohne sich überhaupt in den schwierigen Bereich der automatischen Texterkennung und -interpretation zu begeben. Für den Anwendungszweck reicht es.
Deshalb: Es muss nicht immer das Ziel sein, das „Beste“ herauszuholen. Viel wichtiger und sinnvoller ist es, sich Gedanken zu machen, was angemessen ist.